Data Layouts
A data layout tells Running Reality what type of data is in the data source.
Overview
A data layout tells the Running Reality desktop app what type of data is in the data source. Without a layout, it would not know which data columns or properties represent dates, names, locations, events, or relationships.
Download AppRunning Reality can sometimes suggest a data layout if it finds a date column, but you will have to confirm the historical context. If Running Reality can auto-detect that a column is a date, is that the date of the founding of a city, a birth date, the citation publication date, or another date? Many data sources have location data that is a named location (such as a ship's port of origin), or linked data (such as a geocoder reference ID).
To have this data source appear as a map layer, a minimal layout that identifies the location data is all that is needed. If start and end dates and a name are identified by the data layout, then the map layer can have additional nuance.
Data Layout
A data layout is a list of data fields that correlate a data field within the data source to a type of historical data. Most data sources consist of sets of "records," each for a specific historical subject. Examples of data fields include names, dates, location, and events. Examples of subjects include cities, people, buildings, coins, or artifacts. In some data sources, the records are easy to identify, such as a single row of a spreadsheet. In other sources, such as a large PDF, you may need to describe how to identify a record, such a paragraph or page break or section header.
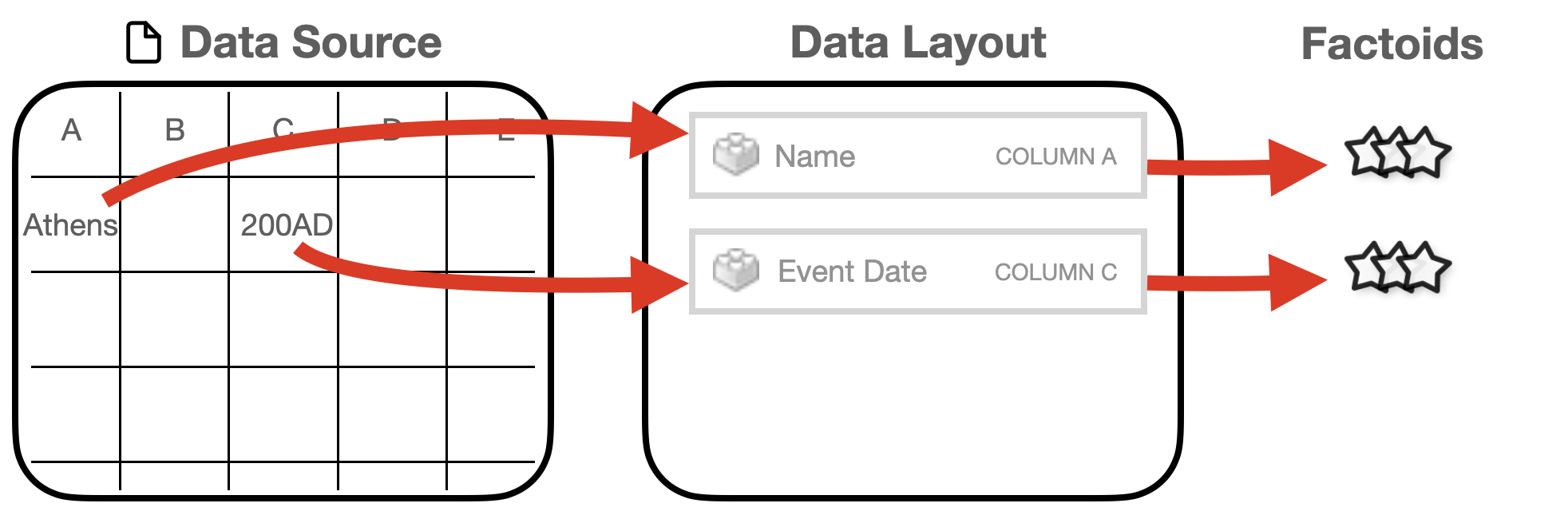
A layout is used by Running Reality to know the historical meaning of the data. First, the data importer uses the layout to extract factoids. Each data field in the layout might result in one (name) or more (movements, altnames) factoids. Second, the layout can enable an in-map layer where each record that has a location can be a point in the map. If the layout also identifies names and dates, those can also be used to render the point only on certain dates and with a name label.
Suggestions
Running Reality can suggest data fields to help you create a layout from scratch. It can be intimidating to start from a completely empty list. Automatic suggestions are shown when fields are needed for name and type or could be beneficial for dates and locations. There is also a "Suggest a layout..." button that will attempt to analyze the data source to find data fields in an easily identifiable format.
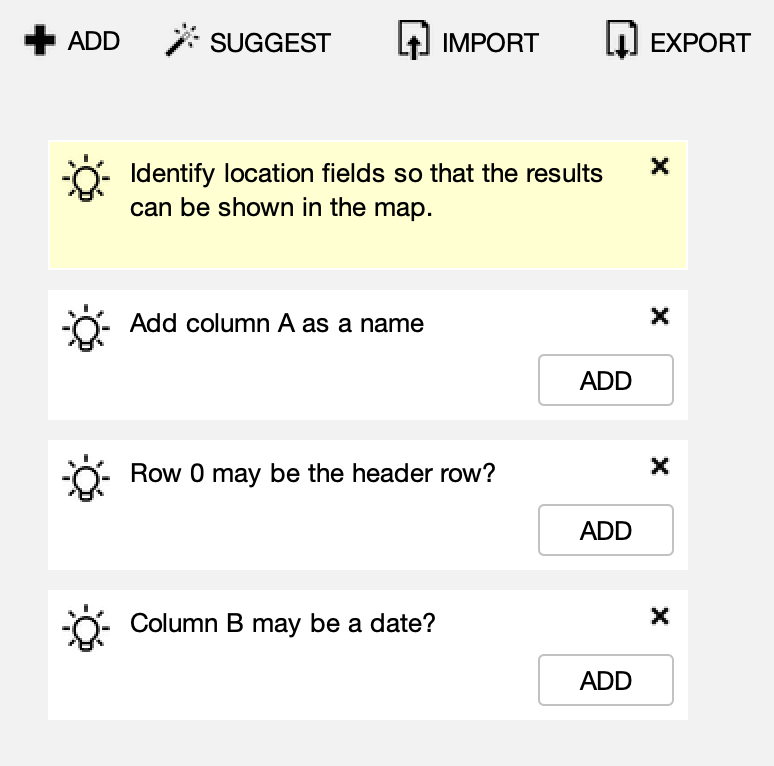
For data tables, you can also start a data field by clicking the header row. This makes it easier to define the record position, i.e. pre-filling out that the data is in column C if you click the Column C header.
Record Fields
The list of available data fields is shown at right. Select a field type to add it to your layout. There are multiple fields of the same type, that each understands different formatting.

Each field has a field type, which is also its default label when you add it to your layout, but you can configure the label to make it easier to understand its meaning. I.e. you might have three date columns and it helps to give them labels so they don't all say just "Date."
The different formats are described in the tool tip text that appears when you hover over a field type.
For instance, "Name" just expects your data to be a plain text name, like a table cell with just "Athens." Then
"NameJSON" expects a more complex name in a JSON snippet like {"name":"Athens"}. These more
complex formats, especially the JSON ones, can be useful if the data is the result of a database query or
Machine Learning assessment (like OpenAI's ChatGPT). There are separate location field types for
latitude and longitude in difference data field, in the same field separated by commas, or in a JSON structure.
There are also location field types for named locations where the importer will then use a geocoder to
translate the data from text to latitude and longitude.
Each field has detailed configuration parameters. These let you operate on data that may not be already clean or which might need formatting adjustments. Most text fields have parameters to exclude certain text, such as parenthetical remarks. Name fields have options to handle blank names or "NA" or to create anonymous names. Date fields can have special formatting to enforce strict date formats or to be more permissive or just to "exhaustively try all parsing options." JSON fields have options to flexibly ignore non-JSON text or to use different key names for key-value pairs.
The number of data fields is always growing as is the list of parameters available. If you need an additional field type, please reach out to ask:
Record Position
The record position abstracts the data source so that the same algorithms can import or create an in-map layer. This lets Running Reality operate on a wide range of data source types and create new, uniform structured data sets.
Each type of data source may have records in a different format and have a different way to identify data fields within records. The is handled by each data field having a record position. The valid positions depend on the data source type. Here are examples:
One type of position is "Global" that can be used in all layouts. A global value is a value that is set for all records, regardless of the record data. If every row in a table is a city, and there is no data column that says "city," then you can set a global data field that sets the type for all records as "City."
A simple table (such as a CSV or XLS file or a SQL database) has records in rows and data fields in columns. So, the record position is a simple column letter:

An RDF file consists of statements in "tuples", where a tuple is a subject → predicate → object. All statements about the same subject become a record. Then the record position is the name of the predicate. For example, Mint of Athens → temporal → 200AD. In this case, the record position is the predicate "temporal."

For text documents (such as PDF, TXT, or HTML), the narrative has no defined records or data fields. Running Reality can pass a block of text to a Machine Learning model (such as OpenAI's Large Language Model (LLM) ChatGPT) with a question. The question becomes the record position, for example "When was the city founded? Format your answer in a JSON structure." With a carefully constructed question that specifies an answer in JSON format, the answer can be passed to the data field to create structured data.

The record position is the central concept that allows Running Reality to operate on such a wide range of data sources.
Advanced
Very complex layouts can be created to handle very complex data. It can be an advantage to not change the complex data source because it might be needed for interoperability with other tools. So, rather than change the data source, you might need to use more complex layouts to describe the historical context of the data for Running Reality to use it.
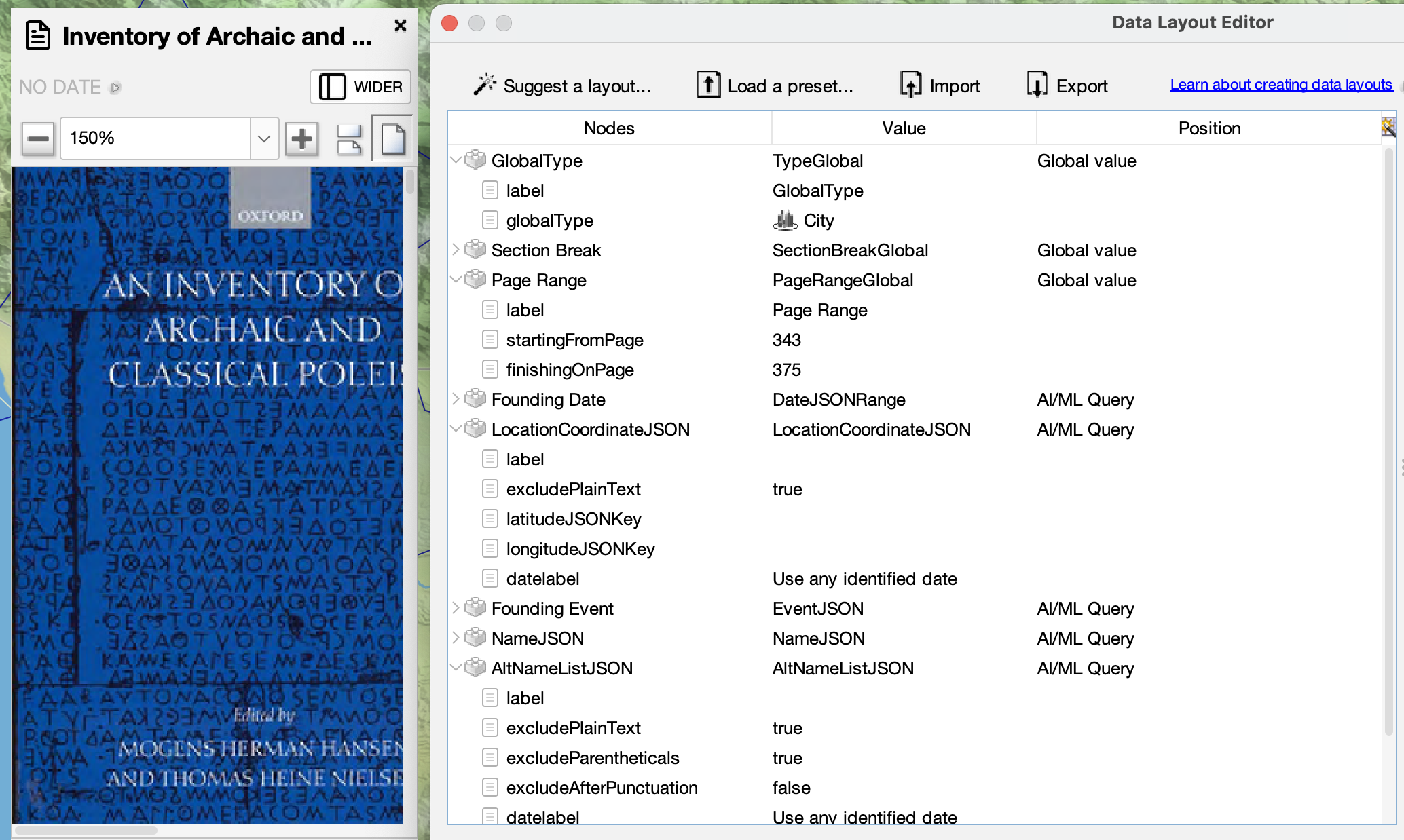
Fields can depend on other fields. The most common case is date fields. A date field might be a standalone field, but it implies a date for other data fields that might be in different columns. To mark a location, you might have the location data (consisting of just the latitude and longitude) depend on a labeled date field. To label one field for use by another, you set the label parameter. A labeled field uses its label in the layout list instead of the default label which is the field type.
Another interdependency is for movements. A movement is a compound field, linked to two or more other labeled fields. A movement required a labeled origin location, a labeled destination location, and a labeled start date. An example is a ship movement where the origin and destination are the names of the two port cities.
For text documents, you may need to specify the page range and the section break that divides records. A long PDF might have many pages without data, such as tables of contents or a bibliography, so a PageRange global field can narrow the pages being processed. Similarly, a global SectionBreak field can specify the REGEX pattern to use to identify each document section that corresponds to a single record for a single subject. For example, a section might start with a number then a city name "75. Athens" to denote the next few paragraphs are data about Athens.
For very complex layouts, you may want to save them to reuse later or to share with other team members who are also operating on the same data source. You can use the "import" and "export" buttons to transfer data fields between layouts.